
Turning the Tide on Customer Churn
Unveiling Churn Dynamics: A Data-Driven Exploration
With extensive experience in assessing the impact of customer churn on revenue and accounts receivable, I leveraged Python to dissect and analyze complex patterns of customer churn. My Master’s in Data Science further enabled me to transform these detailed analyses into actionable insights for reducing churn and enhancing customer retention strategies.
Harnessing Technology: Advanced Tools for Strategic Analysis
My expertise with ERP systems like NetSuite, SAP, and Oracle, combined with SQL skills, enabled efficient handling of large datasets. This project capitalized on Python’s capabilities and libraries such as Pandas and Scikit-Learn for robust predictive modeling, supported by dynamic visualizations with Matplotlib and Seaborn.
Analysis and Methodology: Crafting the Approach for Churn Reduction
The project commenced with an exploratory data analysis to uncover key churn patterns, notably the impact of service calls on churn rates. Although I explored feature engineering techniques such as creating interaction terms and aggregating total minutes, these modifications did not significantly improve model performance and were not included in the final analysis. This phase was vital for determining the most effective data handling techniques, informed by my extensive experience in revenue management and data interpretation across roles at companies like Saba Software and MarketLive.
Optimal Data Synthesis: Balancing and Tuning for Precision
Advanced statistical techniques, such as Stratified K-Fold Cross-Validation and targeted balancing methods like weight adjustments and subsampling, were employed to address the unbalanced nature of the dataset, with an imbalance of approximately 14.6%. These methods allowed for precise model tuning, focusing particularly on recall to minimize the risk of missing true positive churn cases. This focus on thoroughness reflects the rigorous standards required in financial reporting, mirroring the meticulousness I maintained in revenue management.
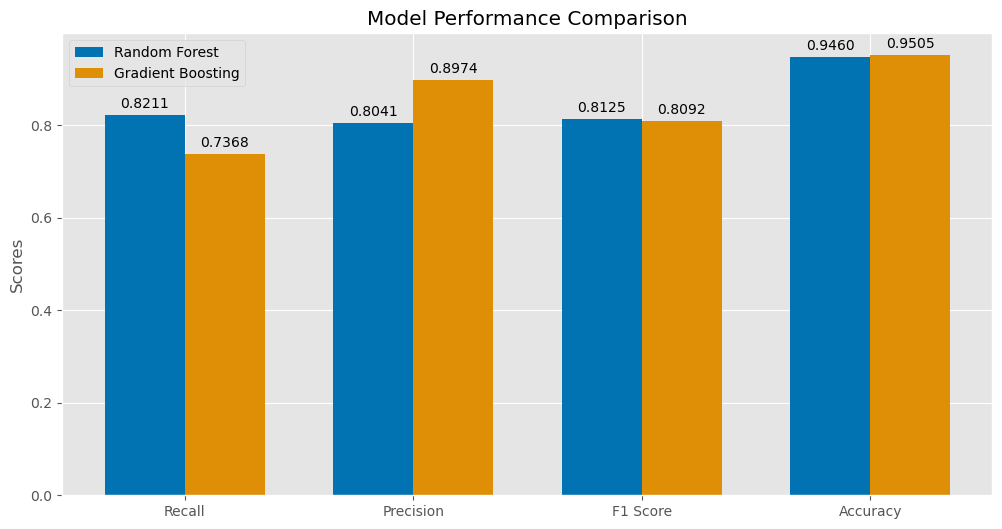
Model Performance: Assessing Metrics for Churn Prediction
Model performance was quantified, highlighting recall. Random Forest achieved a recall of 0.8211, slightly higher than Gradient Boosting’s 0.7368. Both models demonstrated strong precision, F1-scores, and over 94% accuracy, indicative of a well-calibrated balance between recall and precision.
Strategies in Action: Translating Insights into Business Outcomes
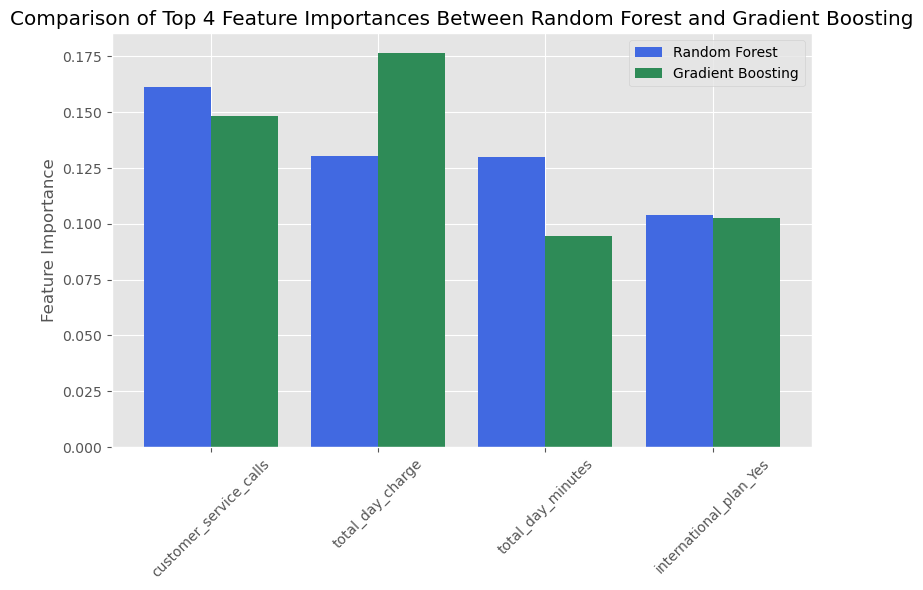
Our analysis surfaced key churn drivers: high usage patterns, frequent service interactions, and certain plan features. Recommendations aimed at improving customer service include implementing robust follow-up procedures post-service calls, personalized pricing strategies responsive to customer usage patterns, and revising international plan offerings to be more competitive—all informed by the data-driven insights from the top feature importances graphed below. These strategies have the potential to enhance customer service and create pricing plans that could improve satisfaction and reduce churn.
Join the Conversation
I invite feedback and discussion on this project and my broader journey into data science. Share ideas and explore synergies with me.
Explore the Full Analysis
Dive deeper into the comprehensive study in my detailed post here.
Technical Deep Dive
For a detailed breakdown, including code and visuals, view the project notebook on NBViewer.