
Machine Learning for Advanced Fraud Detection
Introduction
In the digital age, fraud has become a pervasive issue affecting various industries. Leveraging machine learning for fraud detection offers a robust solution to identify and mitigate fraudulent activities. This post provides an in-depth look at my implementation of fraud detection using advanced machine learning techniques.
Understanding Fraud Detection
Fraud detection involves identifying fraudulent activities in various domains such as finance, e-commerce, and insurance. The primary objective is to accurately distinguish between legitimate and fraudulent transactions or activities, minimizing false positives and negatives.
Data Collection and Preprocessing
- Data Sources: I used the Banksim dataset from Kaggle, which contains synthetically generated transactions. The dataset includes features such as transaction amount, customer details, merchant information, and whether a transaction was fraudulent.
- Data Cleaning: I handled missing values by imputing with median values for numerical features and the most frequent values for categorical features. I also removed duplicates to maintain data integrity.
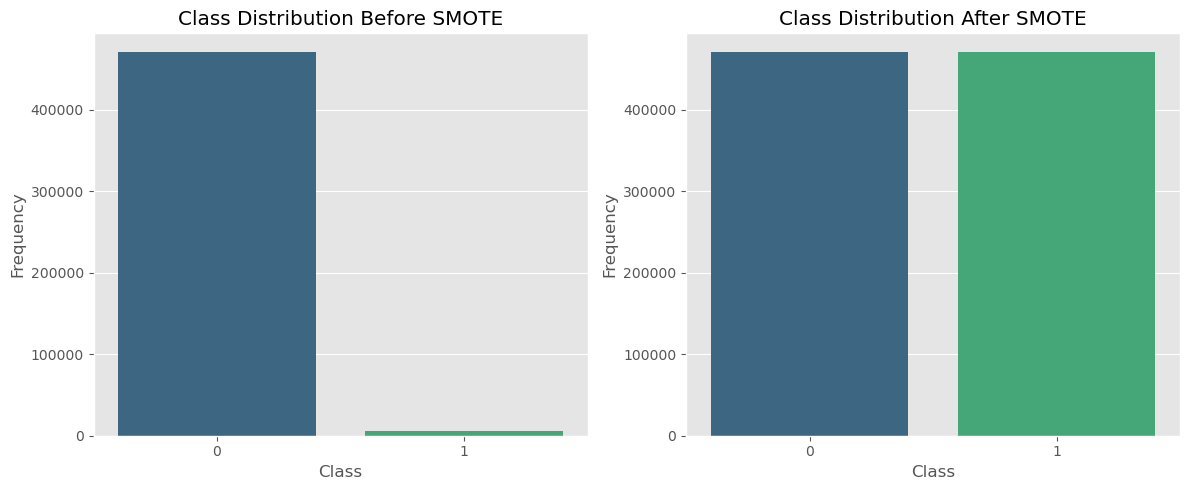
- Class Distribution: I used SMOTE (Synthetic Minority Over-sampling Technique) to handle imbalanced data. This technique helped in balancing the dataset, which is crucial for training effective machine learning models.
Exploratory Data Analysis (EDA)
I conducted EDA to understand the underlying patterns in the data. Visualizations such as histograms, box plots, and correlation matrices revealed insights about the distribution of features and their relationships.
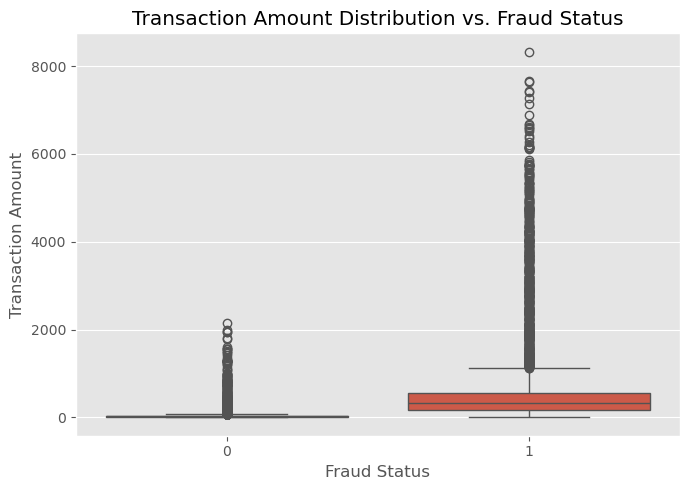
The box plot illustrates that fraudulent transactions tend to have higher transaction amounts compared to non-fraudulent ones, which could be a significant indicator in identifying fraud.
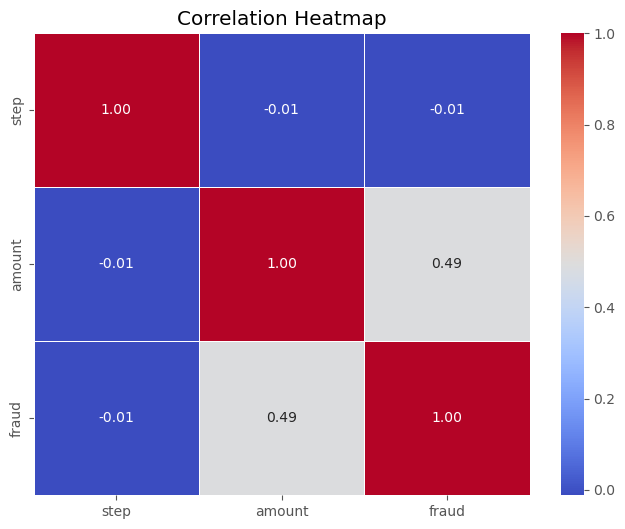
This analysis highlights that while time factors (step) do not significantly influence transaction amounts or fraud occurrences, the transaction amount is a relevant predictor of fraud, underscoring the importance of monitoring larger transactions more closely in fraud detection efforts.
Model Selection and Training
- Supervised Learning Models: I trained a Random Forest model and a Neural Network model on the dataset. The Random Forest model was particularly effective in capturing the complex patterns associated with fraudulent transactions.
- Model Training: I split the data into training (70%) and testing (30%) sets. Cross-validation was used to ensure the models generalize well to unseen data. During training, I monitored metrics such as precision, recall, and F1 score to evaluate model performance.
Neural Network Tuning
The tuning process for the neural network involved several steps to optimize its performance:
model = Sequential([
Dense(units=hp.Int('units', min_value=128, max_value=512, step=32), activation='relu', input_shape=(self.input_shape,)),
Dropout(hp.Float('dropout_rate', min_value=0.1, max_value=0.5, step=0.1)),
Dense(units=hp.Int('units_2', min_value=64, max_value=256, step=32), activation='relu'),
Dropout(hp.Float('dropout_rate_2', min_value=0.1, max_value=0.5, step=0.1)),
Dense(1, activation='sigmoid')
])
model.compile(
optimizer=Adam(hp.Float('learning_rate', min_value=1e-4, max_value=1e-2, sampling='LOG')),
loss='binary_crossentropy',
metrics=[F1Score(), Precision(name='precision'), Recall(name='recall')]
)
- Network Architecture: I experimented with different architectures, including varying the number of hidden layers and neurons per layer. The final model architecture included three hidden layers with 128, 64, and 32 neurons, respectively.
- Activation Functions: I tested various activation functions such as ReLU, tanh, and sigmoid. ReLU provided the best results in terms of convergence speed and performance.
- Optimization Algorithm: I evaluated different optimizers, including Adam, SGD, and RMSprop. Adam optimizer yielded the most consistent and efficient training results.
- Learning Rate: I performed a grid search over learning rates to find the optimal value. A learning rate of 0.001 was selected based on the model’s performance on the validation set.
- Batch Size and Epochs: I experimented with different batch sizes and the number of epochs. A batch size of 32 and training for 50 epochs provided a good balance between training time and model performance.
- Regularization: Techniques such as dropout and L2 regularization were applied to prevent overfitting. A dropout rate of 0.5 was used in the final model.
Random Forest Tuning
The tuning process for the Random Forest model included:
param_grid = {
'n_estimators': randint(100, 300), # Number of trees in the forest: increases model complexity and accuracy.
'max_features': ['sqrt', 'log2'], # Number of features to consider for the best split: helps in reducing overfitting.
'max_depth': randint(10, 40), # Maximum depth of each tree: controls overfitting by limiting how deep trees can grow.
'min_samples_split': randint(2, 10),# Minimum number of samples required to split an internal node: higher numbers reduce model complexity.
'min_samples_leaf': randint(1, 4), # Minimum number of samples required at a leaf node: prevents overfitting on very small leaf sizes.
'bootstrap': [True, False], # Method for sampling data points (with or without replacement).
'class_weight': ['balanced', 'balanced_subsample'] # Handling class imbalance.
}
rf_random_search = RandomizedSearchCV(
estimator=rf,
param_distributions=param_grid,
n_iter=20, # Number of parameter settings sampled.
cv=3, # Number of folds in cross-validator.
scoring=f1_scorer, # Custom F1 scorer defined earlier to optimize for F1 score.
verbose=1, # Controls the verbosity: the higher, the more messages about the process.
random_state=42,
n_jobs=-1 # Use all available cores to perform the computations.
)
- Number of Estimators: I experimented with different numbers of trees in the forest, ranging from 100 to 500. The final model used 300 trees based on the performance metrics.
- Max Depth: I tested various maximum depths for the trees. A max depth of 20 provided the best balance between model complexity and performance.
- Min Samples Split: I varied the minimum number of samples required to split an internal node. A value of 2 was found to be optimal.
- Min Samples Leaf: I experimented with the minimum number of samples required to be at a leaf node. A value of 1 was optimal.
- Bootstrap: I used bootstrapping to create multiple subsets of the dataset for training, which helps in reducing overfitting and improving model robustness.
- Hyperparameter Tuning: I used grid search to find the optimal combination of hyperparameters, which included the number of estimators, max depth, and min samples split.
Evaluation Metrics
The evaluation of the models was conducted using several key metrics:
- Precision: The Neural Network model achieved a precision of 0.87, meaning that 87% of the transactions it identified as fraudulent were actually fraudulent. In contrast, the Random Forest model achieved a precision of 0.63, indicating a higher rate of false positives.
- Recall: The Neural Network model achieved a recall of 0.72, meaning that it correctly identified 72% of all actual fraudulent transactions. The Random Forest model had a recall of 0.89, indicating it was better at capturing fraudulent transactions but with more false positives.
- F1 Score: The Neural Network model achieved an F1 score of 0.79, providing a balance between precision and recall. The Random Forest model had an F1 score of 0.74.
- ROC-AUC: The Neural Network model achieved a ROC-AUC score of 0.97, indicating excellent performance in distinguishing between fraudulent and non-fraudulent transactions. The Random Forest model achieved a perfect ROC-AUC score of 1.00.
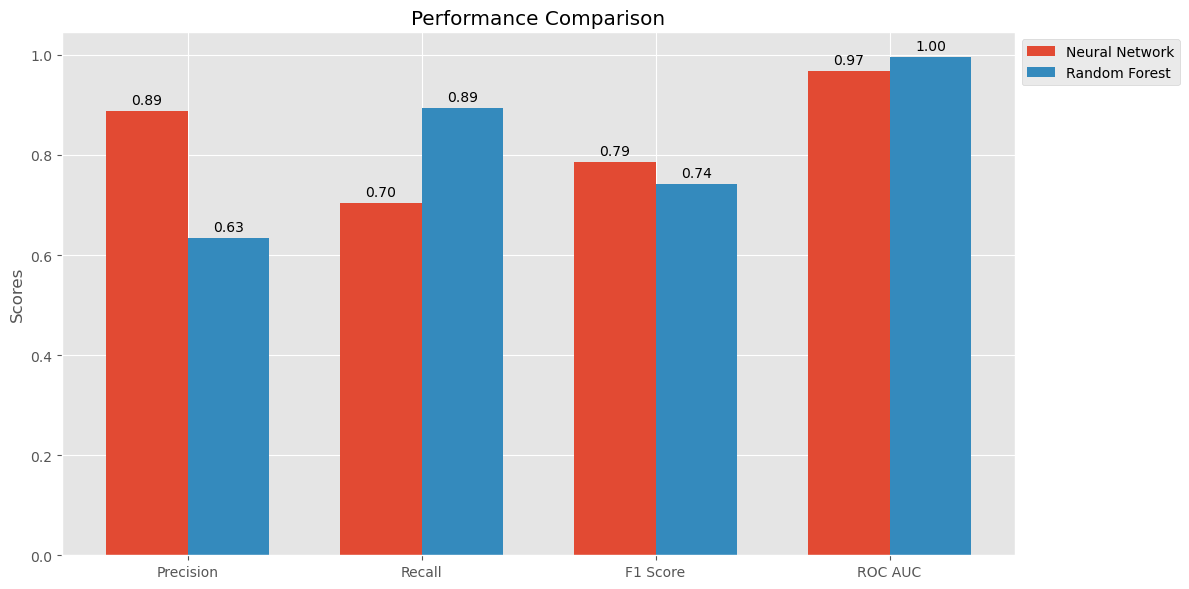
The Random Forest model performs better in terms of recall, indicating it is more effective at identifying a higher number of fraud cases, even if it means catching some false positives.
Additional Evaluation Visualizations
- Precision-Recall Curve: This curve helps in understanding the trade-off between precision and recall for different threshold settings of the model.
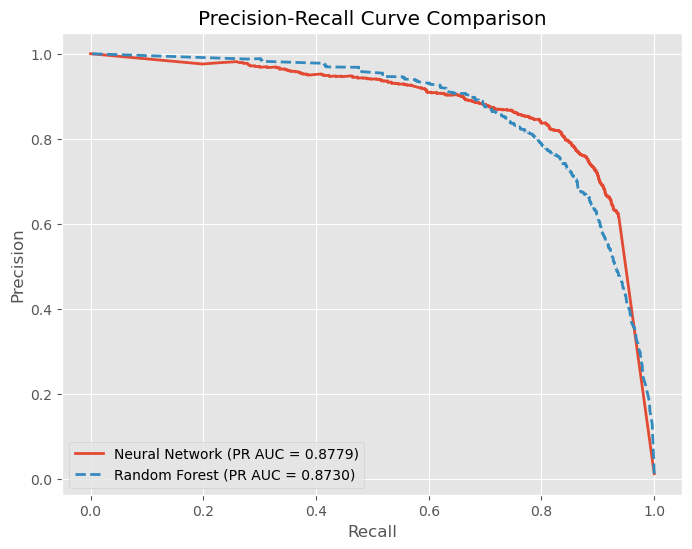
In the context of fraud detection, where both high precision and high recall are crucial, the neural network model performs slightly better than the random forest model. This means that the neural network is more effective in correctly identifying fraudulent transactions while minimizing false positives. However, both models demonstrate strong performance and can be considered effective for fraud detection tasks.
- Cumulative Gain Curve: This curve shows the cumulative gain for the model, indicating the effectiveness of the model in identifying fraudulent transactions early.
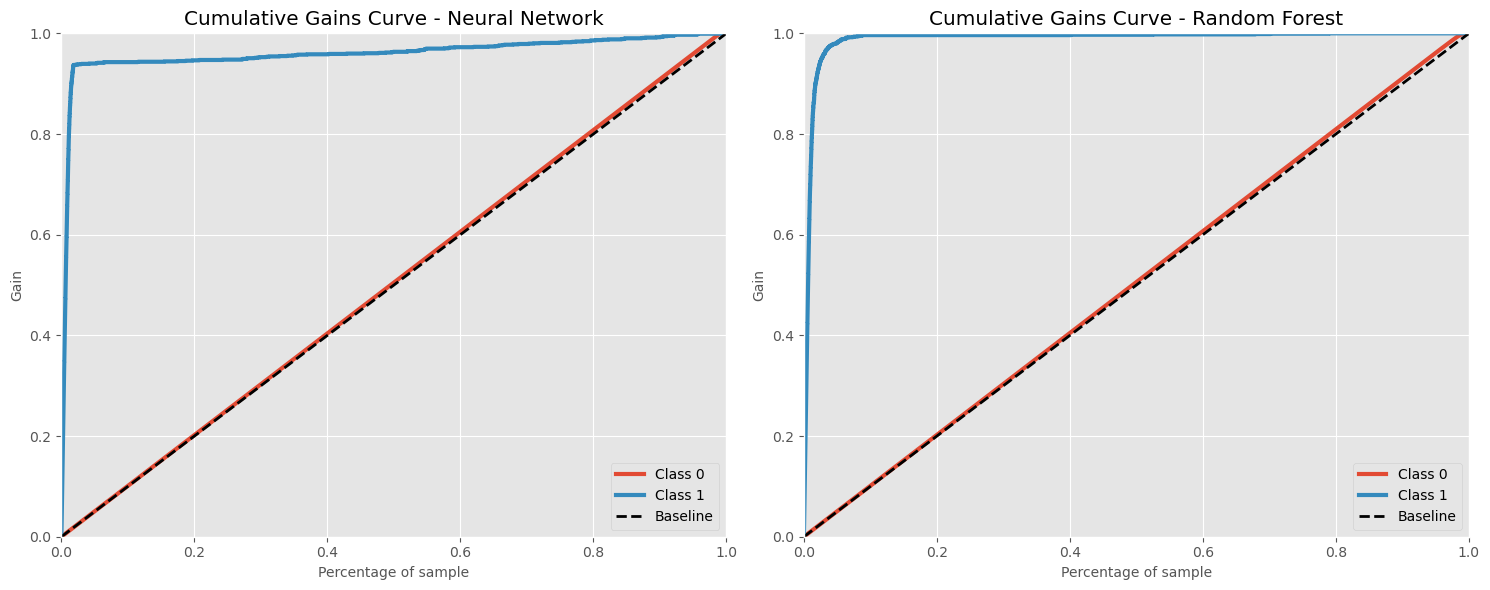
The Cumulative Gains Curves for both models affirm their value in fraud detection systems. They optimize the process by ensuring that the majority of fraudulent transactions are identified quickly, enabling organizations to allocate resources more efficiently and respond more swiftly to potential threats. This capability is essential for maintaining financial security and consumer trust in high-risk environments.
Visualization and Results
- Feature Importance: I plotted the feature importance from the Random Forest model to identify the most influential variables. Features with higher importance scores have a greater impact on the model’s predictions.
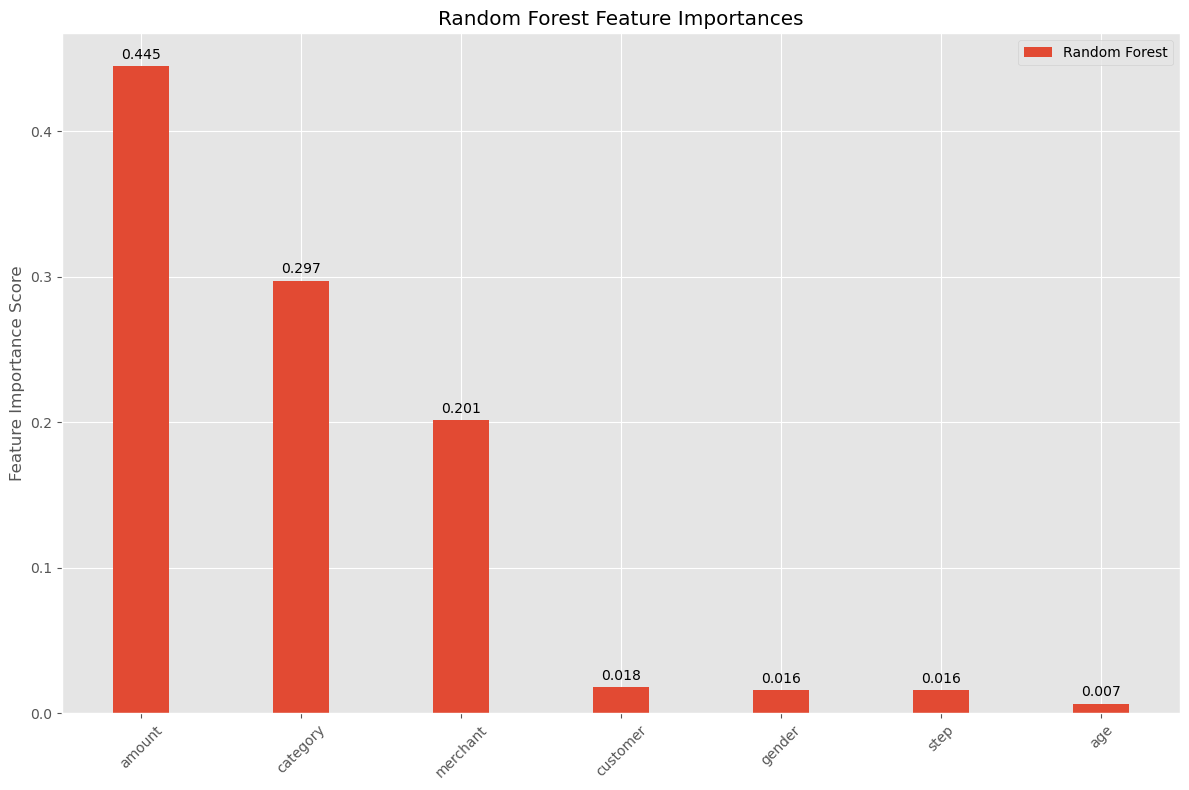
The prominence of ‘amount’, ‘category’, and ‘merchant’ underscores their importance in any fraud detection system. Understanding these key drivers can help in developing more targeted fraud prevention strategies, focusing on the most indicative signs of fraudulent activity.
Business Recommendations
Prioritize High-Impact Features
- Transaction Amount: Implement automated monitoring systems to flag transactions that exceed predefined thresholds based on historical data and typical customer behavior. This can help in quickly identifying and scrutinizing potentially fraudulent large transactions.
- Transaction Category and Merchant Analysis: Develop specialized monitoring rules for categories and merchants identified as higher risk. This could involve more frequent reviews, tighter transaction controls, or automated alerts when transactions in these categories or with these merchants occur.
Leverage Early Detection
- Focus on Early Detection in Transaction Monitoring: Utilize the capability of models to detect fraud early in the transaction process. By setting up systems to prioritize reviews of alerts generated from the most predictive features early, resources can be allocated more effectively, enhancing the speed and accuracy of fraud detection efforts.
Enhance Customer Engagement and Education
- Customer Notifications: Implement real-time notification systems to alert customers of suspicious activities immediately. This not only helps in quick fraud mitigation but also engages customers in securing their transactions.
- Educational Campaigns: Run periodic customer education campaigns about common fraud scenarios and safe transaction practices, particularly focusing on the most vulnerable transaction categories and merchants.
Reflecting on the Journey
Overcoming Challenges and Personal Growth
This project was more than just a technical task; it was a journey of personal and professional growth. The challenges faced, from understanding complex fraud patterns to balancing technical and business insights, have been integral to my development. They pushed me to refine my data processing and analysis skills, emphasizing the importance of adaptability and continuous learning in the dynamic field of data science.
Project Impact and Future Directions
Completing this fraud detection project independently marks a notable milestone in my data science journey. It has not only demonstrated my ability to address complex business challenges with rigorous predictive modeling and thorough data analysis but also sharpened my skills in model evaluation and data-driven decision-making. This experience underlines my capability to derive meaningful insights from intricate data scenarios.
Looking ahead, I am excited to delve deeper into advanced modeling techniques and to work with broader datasets. My commitment to embracing cutting-edge methodologies, like deep learning, highlights my potential as a valuable contributor in data-focused roles. This project has been a testament to my innovative problem-solving and strategic analytical skills, positioning me for future opportunities where I can drive impactful business solutions.
Conclusion
Implementing machine learning for fraud detection significantly enhances the ability to detect and prevent fraudulent activities. By applying these models and techniques, organizations can build robust fraud detection systems that adapt to new challenges and effectively protect their assets.
Discover the Full Story
To explore the full analysis with all executed code, outputs, and visualizations, see the complete notebook on NBViewer.


.jfif)
