
Machine Learning for Advanced Fraud Detection
Overview
With over two decades of experience in accounting and robust expertise in data science, I have developed a sophisticated fraud detection system using various machine learning models. This project aims to accurately identify fraudulent transactions in financial datasets, leveraging my background as a revenue manager to enhance financial data analysis.
The primary goal of this project was to implement machine learning models to detect fraudulent transactions, improving the security and reliability of financial systems. By identifying fraudulent activity, this project aims to minimize financial losses and enhance transaction security.
The Banksim dataset from Kaggle was used, consisting of 594,643 transactions over 180 days, including transaction amounts, customer and merchant details, and fraud indicators.
Technologies and Tools Used
The project was developed in Python, utilizing libraries such as Pandas for data manipulation, Scikit-learn for predictive modeling, and Matplotlib/Seaborn for data visualization. Advanced libraries like TensorFlow were employed to implement the neural network model.
Data Preprocessing
To prepare the data for modeling, I focused on scaling and balancing the dataset:
- Scaling: Numerical features were scaled to ensure uniformity and improve model performance.
- SMOTE: The Synthetic Minority Over-sampling Technique (SMOTE) was applied to address the class imbalance by generating synthetic samples for the minority class (fraudulent transactions).
Exploratory Data Analysis (EDA)
During the EDA phase, I focused on understanding transaction patterns and identifying key indicators of fraud. This included analyzing the distribution of transaction amounts and time steps, as well as identifying high-risk categories and demographics.
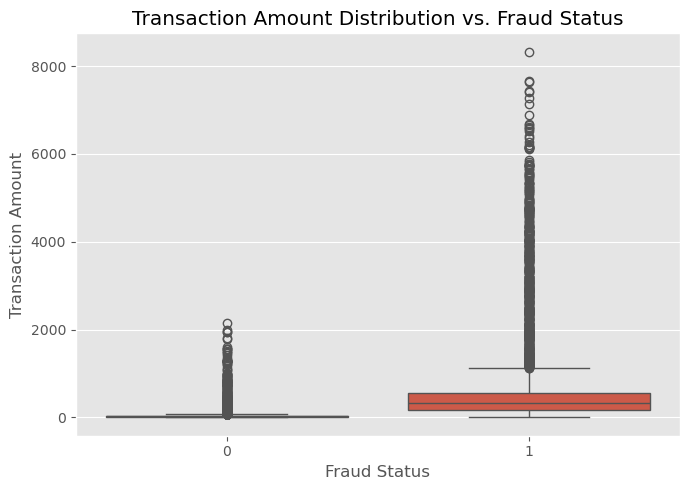
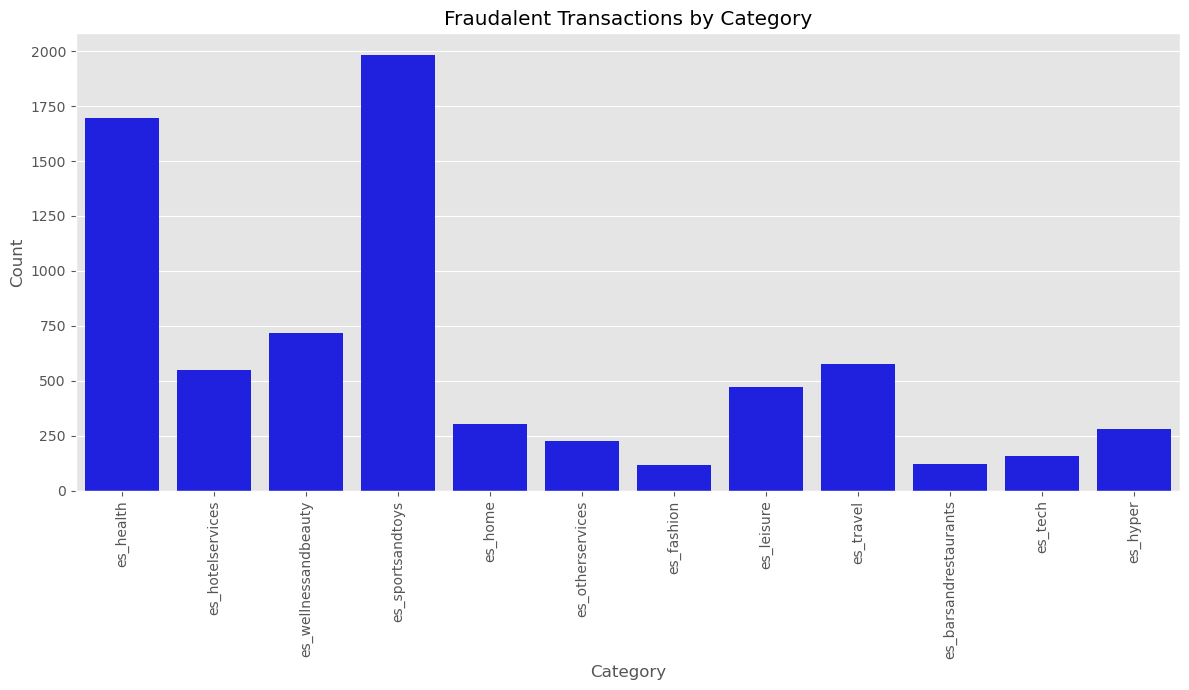
Model Selection
The selection of models posed certain challenges:
- Neural Network Complexity: Adjustments in the multi-layer Neural Network were crucial for the precise detection of fraudulent patterns.
- Random Forest Tuning: Optimization of the Random Forest model through randomized search helped fine-tune its performance.
- Preprocessing Pipelines: Distinct pipelines for each model ensured that data was ideally prepared for analysis.
Results
The models’ performance was evaluated using metrics such as precision, recall, F1-score, and AUC-ROC. Additional evaluation methods included PR Curve, cumulative gain curve, and feature importances. Ensemble methods like Random Forest significantly improved fraud detection accuracy.
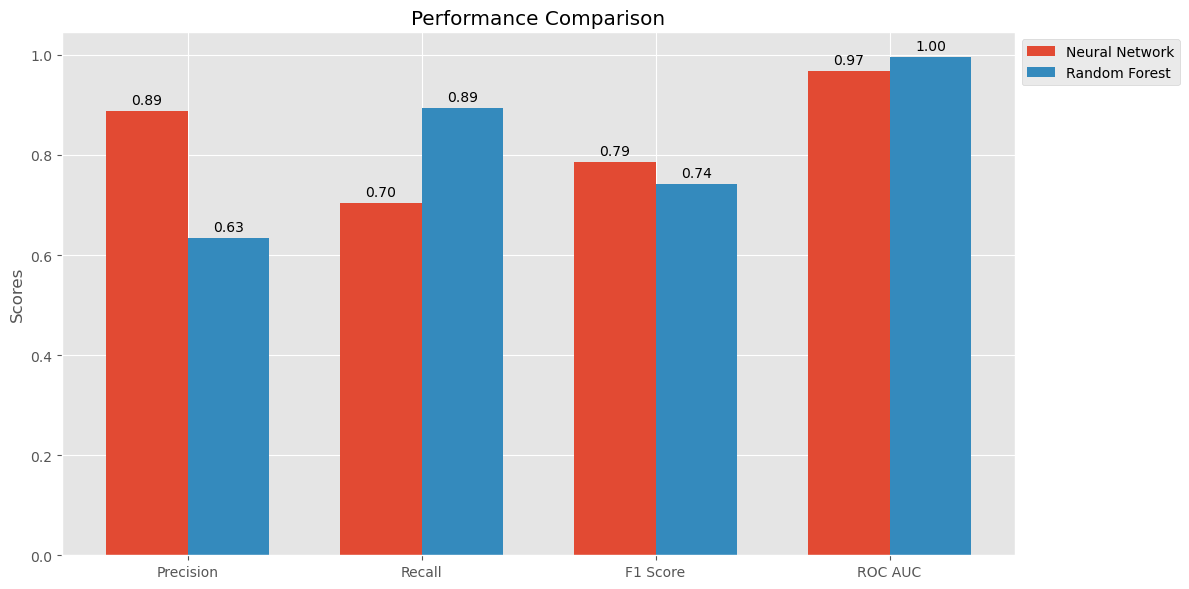
Insights
By identifying high-risk customer segments, I was able to target fraud prevention efforts more effectively. Adjusting model thresholds helped balance false positives and negatives, thereby optimizing detection accuracy and minimizing financial losses.
Recommendations
To enhance fraud detection systems, businesses should consider implementing real-time monitoring to flag suspicious transactions immediately. Investing in advanced machine learning models and regularly updating them with new data can further improve detection accuracy. Additionally, fostering collaboration between data scientists and domain experts can lead to more effective feature engineering and model tuning
Challenges
Managing the imbalanced dataset was challenging, but techniques like SMOTE and undersampling proved effective. Utilizing custom F1 scores allowed me to balance precision and recall, and later focus on recall to detect as many fraudulent transactions as possible.
Conclusion
This project highlights my expertise in handling large datasets, performing thorough data analysis, and developing effective machine learning models for fraud detection. My extensive experience as a revenue manager has equipped me with a strong foundation in financial data analysis, which I applied to enhance my data science skills.
Discover the Full Story
Explore the comprehensive analysis and dive deeper into the data, methodology, and insights by visiting the detailed project page here.
For those interested in the technical details, including the complete code and methodologies, view the project notebook on NBViewer.