
Building a Robust Recommendation System Using Collaborative Filtering
Introduction
In this project, I developed a robust recommendation system utilizing collaborative filtering techniques. The system was designed to predict user preferences based on historical interaction data, aiming to enhance personalized user experiences across various platforms, including e-commerce and streaming services.
Project Objectives
The main objective of this project was to create an effective recommendation system capable of accurately predicting user preferences. The system had to perform well across multiple metrics and align with industry standards for accuracy, precision, and recall.
Dataset Overview
The project used a dataset containing user ratings and movie metadata. This dataset was crucial for building and validating the recommendation models. Data preprocessing steps included handling missing values and creating a user-item matrix to facilitate collaborative filtering.
Technologies and Tools Used
- Programming Language: Python
- Libraries: Pandas, NumPy, Scikit-learn, Seaborn, Matplotlib
- Techniques: Collaborative Filtering (User-Based and Item-Based)
Analysis and Methodology
The methodology revolved around collaborative filtering techniques, both user-based and item-based. These techniques leverage the similarity between users or items to predict preferences. Data preprocessing was a critical step, ensuring that the dataset was clean and suitable for model building. The analysis included visualizing data distribution, building similarity matrices, and evaluating model performance against industry standards.
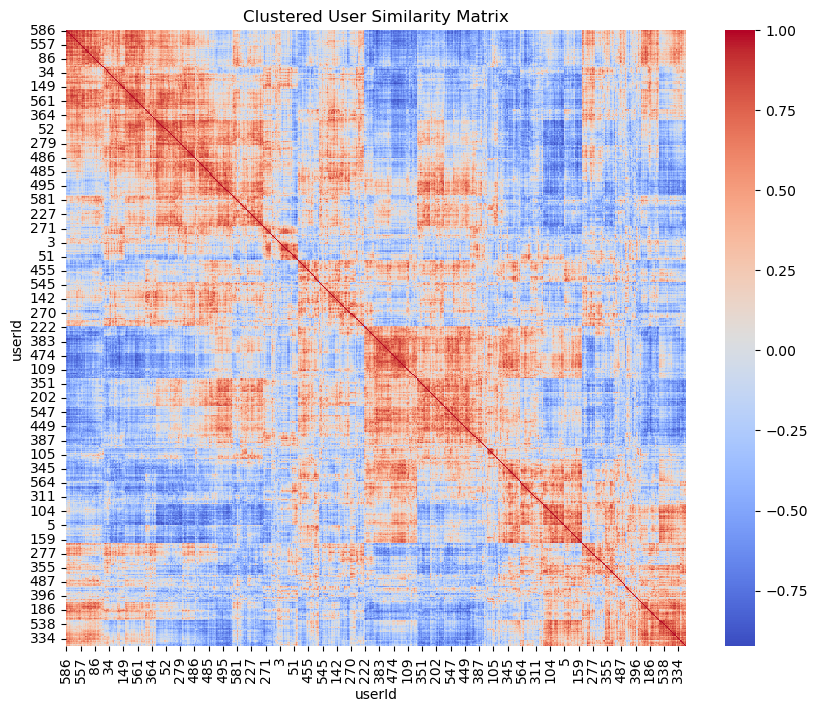
The user similarity matrix was a key component in user-based collaborative filtering, identifying clusters of users with similar preferences. This matrix informed the system’s ability to make personalized recommendations.
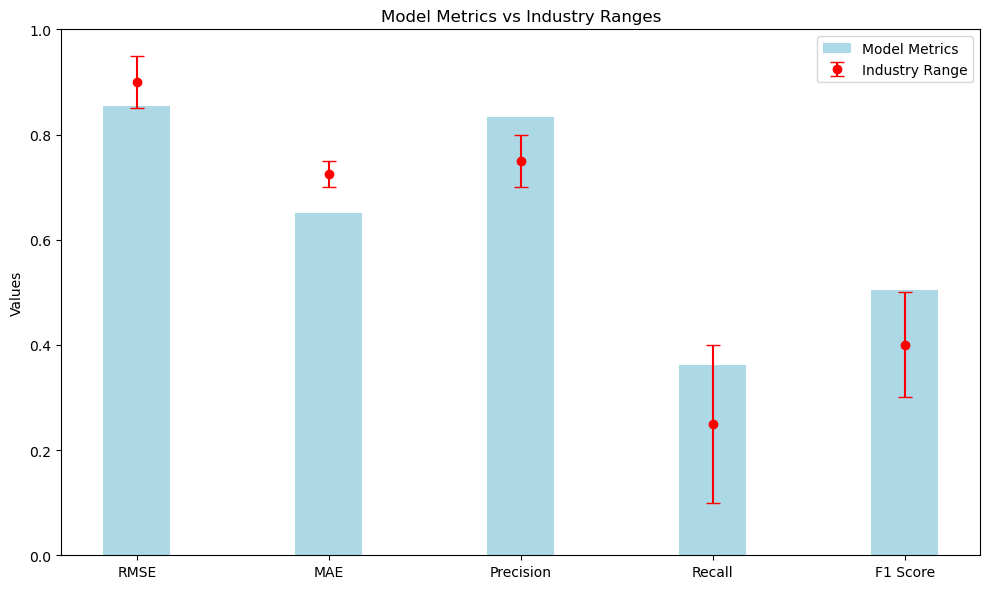
The comparison to industry standards provided critical insights into the system’s effectiveness, ensuring that the model’s performance was competitive with leading recommendation systems.
Actionable Strategies and Key Insights
Key insights from this project include:
- Optimization Opportunities: The low catalog coverage suggests a need to explore and recommend a broader range of items to improve user satisfaction.
- Enhancing Novelty: The high average novelty score highlights the system’s effectiveness in introducing lesser-known items to users, which can drive content discovery.
- Improving Intra-List Diversity: Enhancing diversity within recommendation lists can reduce redundancy and offer users a more varied selection.
Challenges and Learning Experiences
This project presented several challenges, including managing large datasets, addressing data sparsity, and optimizing model performance. My background in accounting and data analysis was instrumental in overcoming these challenges, particularly in data handling and preprocessing.
Reflections and Looking Ahead
Reflecting on this project, I am pleased with the system’s performance across multiple key metrics. Moving forward, there are opportunities to incorporate additional data and explore advanced techniques, such as deep learning-based recommendation algorithms, to further enhance the system’s accuracy and personalization capabilities.
Discover the Full Story
Explore the comprehensive analysis and dive deeper into the data, methodology, and insights by visiting the detailed project page here.
Explore the Technical Journey
For those interested in the technical details, including the complete code and methodologies, view the project notebook on NBViewer here.